Node shell scripting
January 2nd, 2017You want some menial job automated? Some research-y task done? Parse some CSV files, do something with the data? Batch process? Well why not use the language already know instead of learning bash, shell, php scripting or whatever?
Nodejs
Grab the latest version from https://nodejs.org/en/download/current/ and let's go!
Check, check, 1, 2, 3
Open your favorite command prompt/terminal/shell (Mac users, go to Spotlight search, type "Terminal"), then type:
$ node -v
(I use $ to denote something you type in the terminal, you need not type it.)
You should see the version of the Node you just installed displayed in the terminal.

Hello script
Now let's create the simplest script and make sure it works.
$ touch hello.js $ open hello.js
In your editor of choice, type the following in your hello.js file:
console.log(__dirname);
Save the file, now run it:
$ node hello.js
Ta-da!
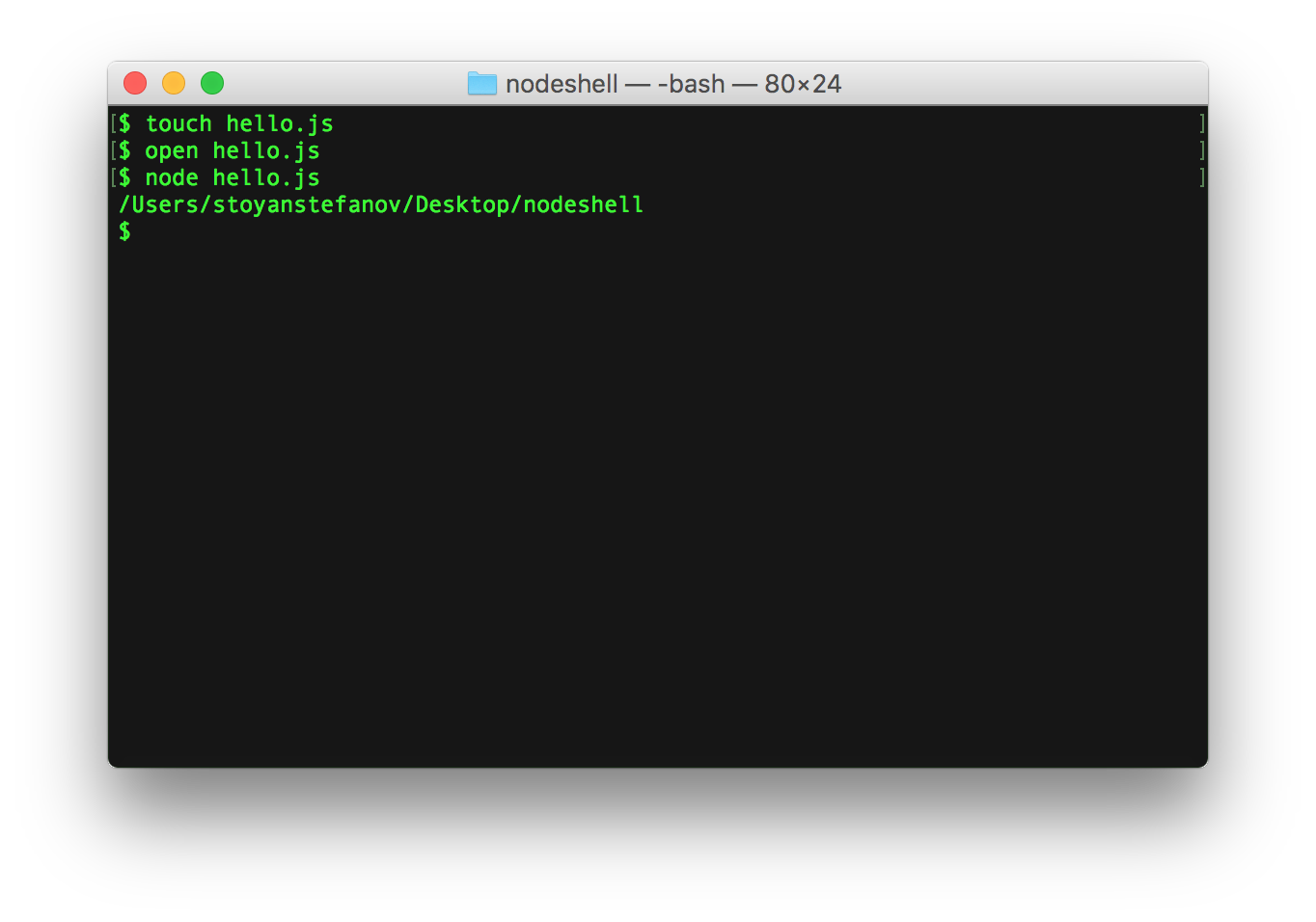
As you can see
- You run a shell script with
$ node scriptname.js - You can print results back to the user with
console.log - You can figure out the directory where your script is located with the constant
__dirname. BTW, similarly__filenamegives you the full path and the name of the script, in this example/Users/stoyanstefanov/Desktop/nodeshell/hello.js
__dirname is useful when you have for example a bunch of files you want to fiddle with in a subdirectory. You don't want to limit where your script can be run from. So it's best to avoid relative paths but always start with __dirname.
Read a directory
Now, imagine you need a script that does something with a list of files you conveniently put in data subdirectory together with your script.
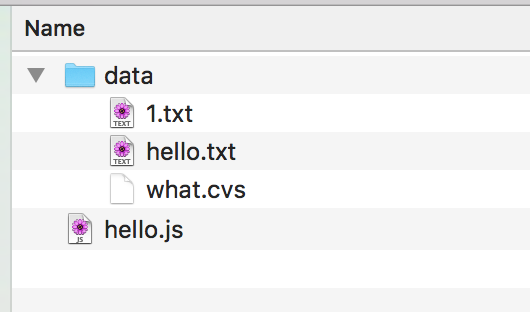
Let's list all the files in this directory using a new script you can call dirlist.js.
$ touch dirlist.js
You start by including two libraries (modules): fs (as in "file system") ans path.
const fs = require('fs');
const path = require('path');
path helps you deal with differences in Windows vs Unix slashes and backslashes and so on. It's alwayts best if you avoid string concatenation and use path's methods instead to make your scripts more reusable and resilient.
fs gives you a number of methods to read, write, delete files and directories.
For the purpose of listing a directory you can use fs.readdir or fs.readdirSync. Let's go with the second. Why? Well, it's simpler. You'll notice several methods have synchonous and asynchronous versions. The async versions are definitely better because they don't block your scripts with one-after-the-other synchronous operations. They tend to make your scripts run faster because you can do several things in parallel. However they are a bit more complicated because you need to provide a callback function to be notified when the async operation is complete.
To keep things simple, sync all the way!
And so function that gives you an array of files in a directory is:
const readDir = fs.readdirSync;
Which directory to list?
const dataDir = path.resolve(__dirname, 'data');
Using resolve you can concatenate the current directory and the data subdirectory without any backslashes, etc.
Now, reading the directory gives you an array and you can simply print the name of each file in the directory in a forEach loop.
readDir(dataDir).forEach(f => console.log(f));
So the whole script is:
const fs = require('fs');
const path = require('path');
const readDir = fs.readdirSync;
const dataDir = path.resolve(__dirname, 'data');
readDir(dataDir).forEach(f => console.log(f));
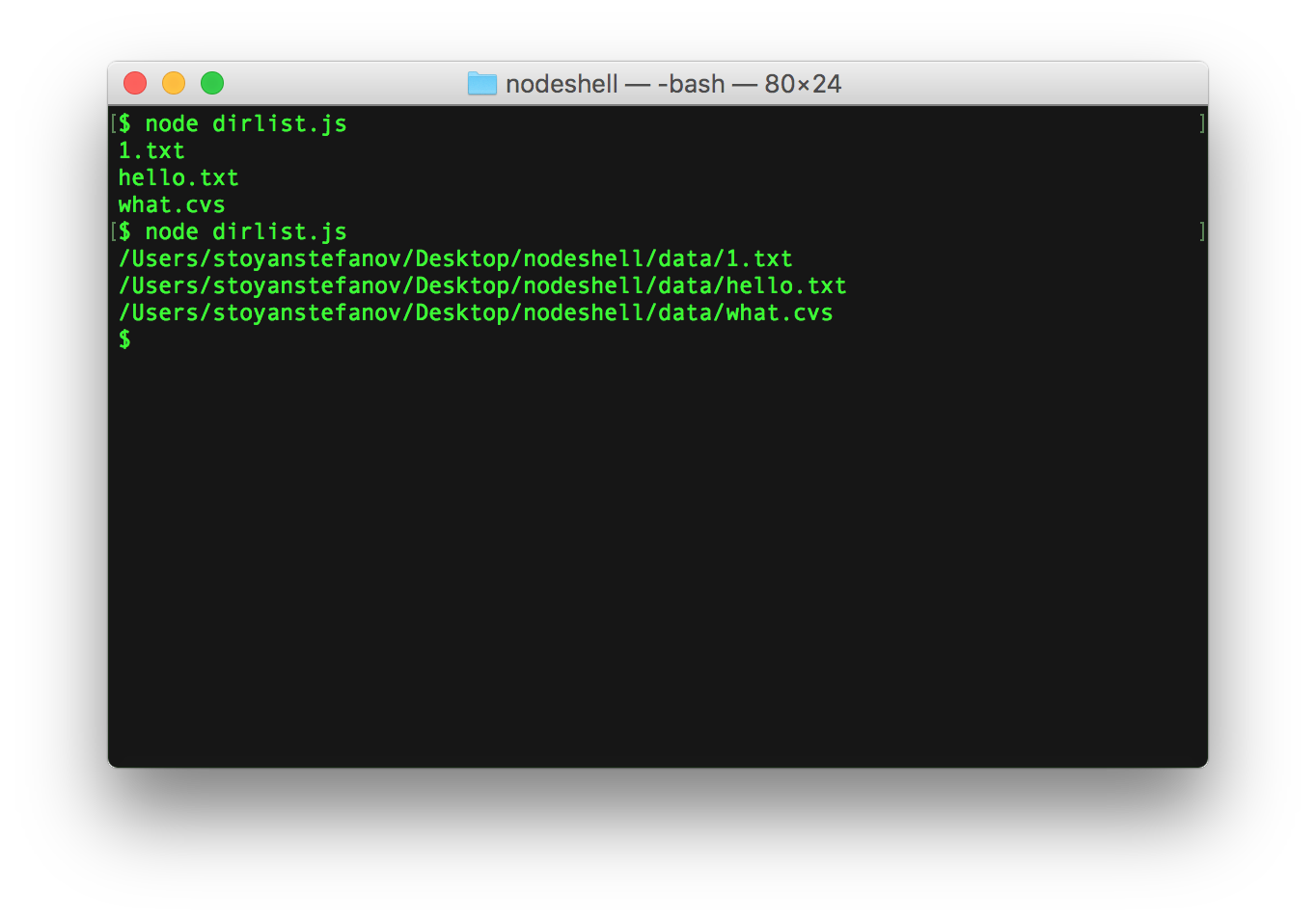
And the script in action....
$ node dirlist.js 1.txt hello.txt what.cvs
You probably want the full path to each file if you're going to read it, so just another path.resolve() call should do the trick:
readDir(dataDir).forEach(f => console.log(path.resolve(dataDir, f)) );
Filtering out things you don't care about
Say you run dirlist.js and spits out something like:
$ node dirlist.js /Users/stoyanstefanov/Desktop/nodeshell/data/.DS_Store /Users/stoyanstefanov/Desktop/nodeshell/data/1.txt /Users/stoyanstefanov/Desktop/nodeshell/data/hello.txt /Users/stoyanstefanov/Desktop/nodeshell/data/moar-data /Users/stoyanstefanov/Desktop/nodeshell/data/what.cvs
Darn Dot-files
There's a .DS_Store file in there, some Max OS garbage you've no use for. Let's remove it from the list of files. You can simply check if the file name starts with a dot (.), like so...
Before:
readDir(dataDir).forEach(f => console.log(path.resolve(dataDir, f)) );
After:
readDir(dataDir).forEach(f => {
if (f.startsWith('.')) {
return; // no .DS_Store etc, thank you
}
const file = path.resolve(dataDir, f);
console.log(file);
});
Files only
How about removing the moar-data directory from the list? You only care about files. There's a stat() method in the fs module that can help here. More specifically, the sync version, statSync().
const stat = fs.statSync;
Calling this method on a file gives you properties (such as file creation time) and methods (such as isDirectory()). Here's how you can filter out directories:
readDir(dataDir).forEach(f => {
if (f.startsWith('.')) {
return; // no .DS_Store etc, thank you
}
const file = path.resolve(dataDir, f);
const stats = stat(file);
if (stats.isDirectory()) {
return; // files only shall pass
}
console.log(file);
});
Now the list contains interesting files only:
$ node dirlist.js /Users/stoyanstefanov/Desktop/nodeshell/data/1.txt /Users/stoyanstefanov/Desktop/nodeshell/data/hello.txt /Users/stoyanstefanov/Desktop/nodeshell/data/what.cvs
Tip:
stats.sizegives you file size.
txt files only
And what if this script only works with text files? Your friend is path.extname(file).
if (path.extname(file) !== '.txt') {
return; // actually text files only
}
Tip: explore what
path.parse()can do for you. E.g.console.log( require('path').parse(__filename) );You should see something like:
{ root: '/', dir: '/Users/stoyanstefanov/Desktop/nodeshell', base: 'dirlist.js', ext: '.js', name: 'dirlist' }
Recursive directory listing
What if the subdirectory moar-data contains additional files you're interested in? Let's list your main directory and its subdirectories and their subdirectories. In other words, list recursively.
All you need to do is put your forEach loop into a function listFiles so it an be reused. This function takes any directory as input (listFiles(dir)), lists it and if it finds that one of the items in the list is another directory (stats.isDirectory()) it navigates into the new directory, instead of ignoring it like before.
const fs = require('fs');
const path = require('path');
const readDir = fs.readdirSync;
const stat = fs.statSync;
const dataDir = path.resolve(__dirname, 'data');
function listFiles(dir) {
readDir(dir).forEach(f => {
if (f.startsWith('.')) {
return; // no .DS_Store etc, thank you
}
const file = path.resolve(dir, f);
const stats = stat(file);
if (stats.isDirectory()) {
return listFiles(file);
}
if (path.extname(file) !== '.txt') {
return; // actually text files only
}
console.log(file);
});
}
listFiles(dataDir);
The script in action:
$ node dirlist-recursive.js /Users/stoyanstefanov/Desktop/nodeshell/data/1.txt /Users/stoyanstefanov/Desktop/nodeshell/data/hello.txt /Users/stoyanstefanov/Desktop/nodeshell/data/moar-data/2.txt /Users/stoyanstefanov/Desktop/nodeshell/data/moar-data/bye.txt /Users/stoyanstefanov/Desktop/nodeshell/data/moar-data/even-more/nomore.txt
Reading files
/* TODO */
Parsing file contents
/* TODO */
Creating directories
/* TODO */
Writing files
To create a blank file called hello.md in a directory called data/ (which is a subdirectory to where your script lives) you go:
const fs = require('fs');
const path = require('path');
const outputDir = path.resolve(__dirname, './data');
fs.writeFile(outputDir + '/hello.md', '', () => {});
The call to fs.writeFile() takes arguments:
- file name
- contents to write to the file, in this case - nothing
- optional options, e.g. file permissions, in this case skipped completely
- a callback function (in this case empty) you can use to tell if there was an error creating this file
process
Where am I?
There's a global `process` that can give such vital advise as: "what is the Current Working Directory"
console.log('Starting here: ' + process.cwd());
I'm done!
Another thing hanging off `process` is `exit()` which kills the execution of the current script. You can also provide exit codes in case your script A is run by another script B and B wants to know whether A managed to finish successfully.
Generally exit code 0 means all is fine, 1 and above is an error.
// yikes! process.exit(1)
Executing other command-line tools
/* TODO */
The Web
Dealing with URLs
/* TODO */
cURL
/* TODO */
Scraping with PhantomJS
/* TODO */
Reading JSON files
Reading JSON files is as simple as just require()-ing them. When you require a JSON file, it's read, parsed (e.g. with JSON.parse()) and the JS object is returned to you.
Here's how to read the first element of the first element of the arrays stored in JSON files in ./data/json
const fs = require('fs');
const path = require('path');
const readDir = fs.readdirSync;
const dataDir = path.resolve(__dirname, './data/json');
readDir(dataDir).forEach(f => {
if (f.startsWith('.')) {
return; // no .DS_Store etc, thank you
}
const file = path.resolve(dataDir, f);
const jsonData = require(file);
console.log(jsonData[0][0]);
});
Usage:
$ node json-read.js A cappella Affettuoso
And here's what the first JSON fille's contents that we just read looks like:
[
[
"A cappella",
"in chapel style",
"Sung with no (instrumental) accompaniment, has lots of harmonizing"
],
....
Writing JSON files
While reading some JSON files (example above) you notice that they contain arrays (rows) and each row's second element (index 1) is lowercase. How about updating all these JSON files and capitalizing the first letter?
After reading the contents on the file into an object with const jsonData = require(file);, all you do is loop over the data, massage the [1]'th element and update the jsonData. After the loop, you have the updated data. Time to turn that data object to a pretty string with 2 spaces indentation via JSON.stringify(jsonData, null, 2). Finally, use writeFileSync() from the file system module to write the string to a file on the disk:
fs.writeFileSync('path/to/file', stringContents);
Here's the complete example:
const fs = require('fs');
const path = require('path');
const readDir = fs.readdirSync;
const dataDir = path.resolve(__dirname, './data/json');
readDir(dataDir).forEach(f => {
if (f.startsWith('.')) {
return; // no .DS_Store etc, thank you
}
const file = path.resolve(dataDir, f);
const jsonData = require(file);
jsonData.forEach((row, idx) => {
jsonData[idx][1] = row[1].charAt(0).toUpperCase() + row[1].substring(1);
});
fs.writeFileSync(file, JSON.stringify(jsonData, null, 2));
});
Using third party modules
/* TODO */
Taking command line arguments
Arguments array
You can read arguments passed to your script using process.argv. The first two arguments are:
- the node executable
- the path to the script
To test, put this in arg.js
console.log(process.argv);
Running as always...
$ node arg.js [ '/usr/local/bin/node', '/Users/stoyanstefanov/Desktop/nodeshell/arg.js' ]
Running with more arguments...
$ node arg.js hello "hi there" [ '/usr/local/bin/node', '/Users/stoyanstefanov/Desktop/nodeshell/arg.js', 'hello', 'hi there' ]
You rarely need the first two arguments. To get the "real" ones, you simply access the elements of the arguments array as any other JavaScript array.
For example you can require the user to provide you with 2 arguments or refuse to do anything otherwise.
if (process.argv.length < 4) {
console.log('this script requires two arguments');
process.exit(1);
} else {
console.log('Arg 1: ', process.argv[2]);
console.log('Arg 2: ', process.argv[3]);
}
Testing...
$ node arg-idx.js this script requires two arguments $ node arg-idx.js hello there Arg 1: hello Arg 2: there
An array of interesting args only
You can slice away the first two arguments as they are mostly useless and focus on the rest. Easy:
const allArgs = process.argv.slice(2); console.log(allArgs);
Testing:
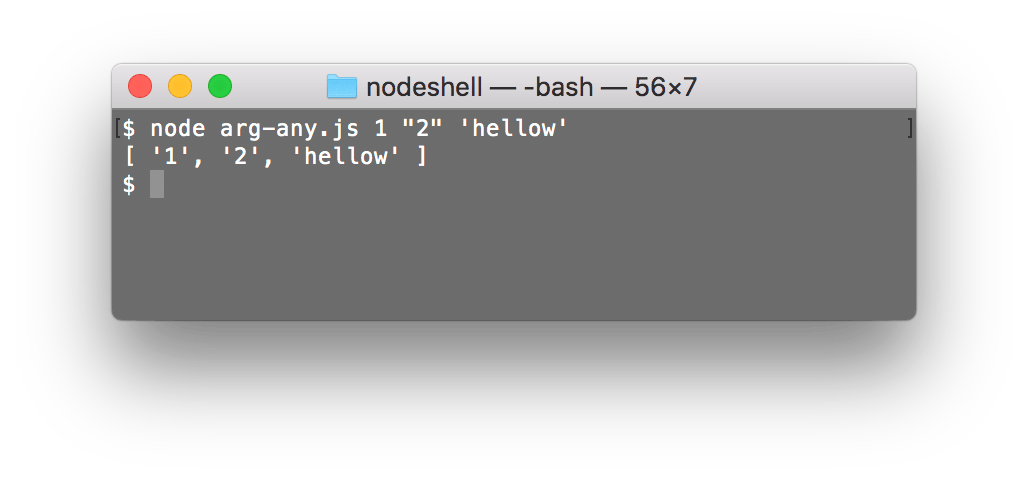
As you can see, any quotes are conveniently gone.
commander
Bells & whistles
Colored output
Printing out text with special escape codes can produce output with different background or foreground colors, underline, bold, blink... Let's see an example.
// print the word "Error" in red
console.log('\x1B[31mError\x1B[39m');
// "Success" is green
console.log('\x1B[32mSuccess\x1B[39m');
Unicode
You can also add Unicode characters to spice things up:
// print the word "Error" in red
console.log('\x1B[31m✖ Error\x1B[39m');
// "Success" is green
console.log('\x1B[32m✔ Success\x1B[39m');
Result:
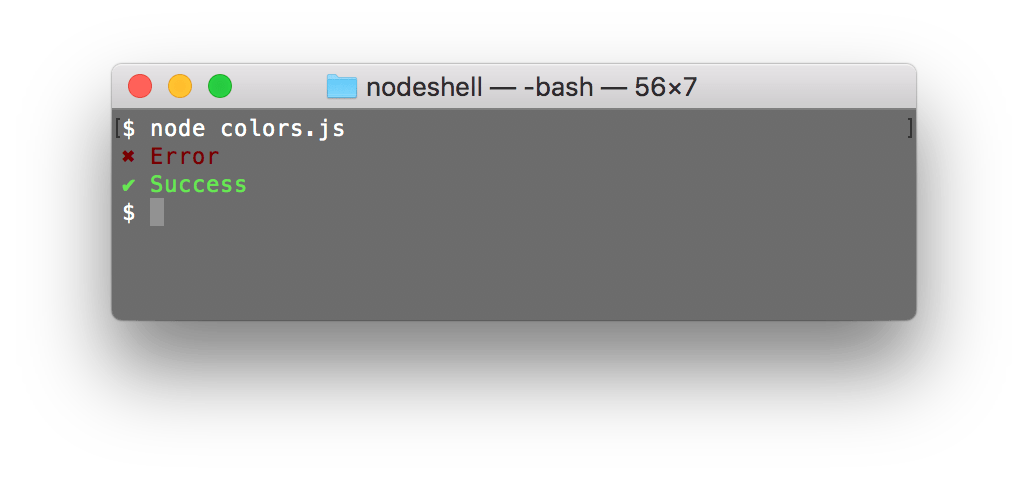
ANSI escape codes
These weird characters surrounding the words Error and Success were ANSI escape code, you can learn a lot more about what they mean and how to use them here.
Project: DIY unit testing scripts
/* TODO */
Publishing your script to NPM
/* TODO */








